
大模型像“大脑”,AI Agent 像“带大脑、记忆、工具、手脚、流程和安全边界的执行系统”。
一个 LLM 或 MLLM 可以是 Agent 的核心,但 Agent 不是一个模型。它是围绕模型搭出来的一套闭环执行架构:理解目标、组织上下文、拆解任务、调用工具、观察结果、修正计划,最后交付结果。
这篇文章按四层来讲:本质、名词、项目、架构图。
1. Agent 的本质:从回答系统到执行系统#
可以先把 AI Agent 抽象成一个公式:
AI Agent = LLM / MLLM
+ Context
+ Memory
+ Planning
+ Tools / Skills
+ Action Runtime
+ Observation
+ Feedback
+ Guardrails其中最重要的不是某一个模块,而是闭环:
目标 → 上下文 → 模型决策 → 规划 → 工具调用 → 观察结果 → 反馈修正 → 再决策没有这个闭环,系统更像 Chatbot;有了这个闭环,才开始接近 Agent。ReAct 范式的核心也是让模型交替地产生推理和行动,并把外部环境返回的 observation 放回下一轮决策里。
| 组成 | 作用 | 类比 |
|---|---|---|
| LLM / MLLM | 理解、推理、生成决策 | 大脑 |
| Context | 当前任务能看到的信息 | 桌面上摊开的资料 |
| Memory | 保存历史、偏好、经验 | 笔记本 / 档案柜 |
| Planning | 把大目标拆成步骤 | 项目经理 |
| Tools / Skills | 搜索、代码、浏览器、数据库、邮件等能力 | 手和工具箱 |
| Action Runtime | 真实执行工具调用和系统动作 | 工作台 |
| Observation | 执行后的返回结果 | 实验结果 |
| Feedback | 评估、修正、重试、沉淀经验 | 复盘会议 |
| Guardrails | 权限、安全、审计、人工确认 | 安保和审批流程 |
MLLM 和 Agent 的区别#
MLLM 是 Multimodal Large Language Model,多模态大模型,擅长理解和生成文本、图片、音频、视频等内容。但单独一个 MLLM 通常还是“被动回答系统”。Agent 则是“主动执行系统”。
| 对比维度 | 单独的 MLLM | AI Agent |
|---|---|---|
| 核心定位 | 理解与生成 | 规划、执行、反馈、交付 |
| 交互方式 | 用户问,模型答 | 用户给目标,Agent 拆解并执行 |
| 运行模式 | 一次或少数几次模型调用 | 多轮循环:计划 → 行动 → 观察 → 修正 |
| 是否能动手 | 本身不能真正操作外部世界 | 可通过工具、API、浏览器、代码环境执行动作 |
| 状态能力 | 主要依赖上下文窗口 | 可接入短期记忆、长期记忆、向量库、任务状态 |
| 错误处理 | 回答错了通常只能重新问 | 可以观察失败、重试、换工具、更新计划 |
| 风险形态 | 主要是内容错误和幻觉 | 还包括误删文件、乱发邮件、越权调用 API |
一句话总结:
MLLM 是“会看会说的大脑”;Agent 是“让大脑接上眼睛、手、记忆、工具和执行流程后的系统”。
2. Agent 领域核心名词#
下面不是词典式罗列,而是按工程位置分组。理解这些词,本质上就是理解一个 Agent 系统里有哪些层。
基础层:模型与上下文#
Agent:以模型为核心,能够感知环境、规划步骤、调用工具、执行动作,并根据反馈调整行为的系统。它不是“回答问题的人”,而是“能拿着目标去完成事的执行者”。
LLM:主要处理文本理解、推理和生成的大语言模型。
MLLM:能处理文本、图像、音频、视频等多模态输入或输出的大模型。它让 Agent 有更强的感知能力,但不自动等于 Agent。
Context:当前模型调用时能看到的全部信息,包括用户任务、系统提示、历史消息、工具结果、文件内容、检索资料等。
Context Window:模型一次能处理的最大上下文容量。窗口越大,能摆上桌面的资料越多,但仍然需要筛选和排序。
Context Engineering:在有限窗口里选择、压缩、排序和注入最有用的信息。Agent 的稳定性很大程度取决于上下文工程,而不是只取决于模型大小。
Prompt / System Prompt / Developer Instruction:分别对应任务说明、系统级规则、应用开发者设定的行为边界。它们定义 Agent 怎么工作、不能做什么、什么时候需要确认。
记忆层:短期、长期和可检索经验#
Memory:Agent 保存历史信息、用户偏好、任务状态、经验教训的机制。
Short-term Memory:当前任务内临时保存的信息,例如刚刚的工具结果、当前计划、未完成步骤。
Long-term Memory:跨会话保存的稳定信息,例如用户偏好、项目背景、历史经验。
Episodic / Semantic / Procedural Memory:分别对应“某次任务发生了什么”“稳定知识是什么”“这类事情应该怎么做”。很多 Agent 的 Skills 本质上就是程序性记忆。
Embedding / Vector Store / RAG:Embedding 把内容变成语义向量;Vector Store 用相似度检索资料;RAG 则是在回答或行动前先检索知识,再把相关资料放进上下文。
规划层:从目标到步骤#
Planning:把复杂目标拆成可执行步骤,并决定顺序。
Task Decomposition:任务拆解。例如把“调研竞品并发邮件”拆成搜索、筛选、表格、报告、草拟邮件、确认发送。
Planner / Executor:Planner 负责生成计划,Executor 负责按计划执行工具调用。实际系统里二者可以是同一个模型,也可以拆成不同模块。
Router / Orchestrator:Router 选择模型、工具或子 Agent;Orchestrator 负责协调多个工具、流程和子 Agent。
Sub-agent / Multi-agent System:子 Agent 负责专项任务,多 Agent 系统则像一个团队,有研究员、工程师、评审员等不同角色。
Handoff:一个 Agent 把任务交给更合适的 Agent 或人类。交接质量取决于它能否把目标、上下文、已做动作、剩余风险说清楚。
行动层:工具、技能与 MCP#
Action:Agent 决定并执行的外部操作,例如搜索网页、调用 API、写文件、运行命令、发送邮件。
Observation:行动后环境返回的信息,例如网页内容、命令行输出、API 响应、错误日志、截图、文件变化。
Tool:可被 Agent 调用的外部函数、API、浏览器、数据库、代码解释器等。
Skill:比 Tool 更高层的可复用任务能力。Tool 像“菜刀”,Skill 像“会做一道菜的流程”。
Function Calling:模型按结构化 schema 输出函数名和参数,由系统真正执行函数。
Tool Schema / Tool Registry:Tool Schema 是工具说明书,描述参数、返回值、限制条件;Tool Registry 是可用工具目录。
MCP:Model Context Protocol,是一个开放协议,用标准方式把 LLM 应用连接到外部数据源和工具。官方规范把 MCP 定位为连接 LLM 应用与外部 context、tools、workflows 的协议;MCP 架构里有 Host、Client、Server 三个关键角色。
| MCP 角色 | 含义 | 类比 |
|---|---|---|
| MCP Host | 承载 AI 应用的一方,例如 IDE、桌面助手、聊天应用 | 插排本体 |
| MCP Client | Host 内部负责连接某个 MCP Server 的组件 | 接口转换器 |
| MCP Server | 暴露工具、资源和 prompt 的服务 | 被插上的外设 |
MCP 解决的是“外部能力怎么标准接入”的问题,不直接规定 Agent 怎么规划、怎么记忆、怎么做安全决策。
闭环层:反馈、反思与停止条件#
Feedback:系统根据工具结果、环境变化、人类评价或模型自评来修正后续行为。
Reflection:Agent 总结失败原因和经验教训,用于下一轮尝试或写入长期记忆。
Critic / Evaluator / Judge:专门评估计划、答案、动作是否正确的模块。它可以是规则、测试、另一个模型,也可以是人工审核。
Trajectory / Trace:Trajectory 是一次任务从目标到结果的完整路径;Trace 更工程化,包含模型输入输出、工具调用、耗时、错误等日志。
Stop Condition:决定 Agent 何时停止,例如目标完成、达到最大步数、连续失败、需要人工确认。
安全与运行层#
Agent Runtime / Harness:承载模型调用、工具调用、状态管理、权限控制、日志追踪的系统外壳。
Hooks:在模型调用前后、工具调用前后、出错时、任务结束时触发的生命周期回调。
Sandbox:隔离执行环境,限制 Agent 对文件、网络、系统命令的影响范围。
Guardrails:权限、安全、过滤、审计、审批等约束机制的总称。
Human-in-the-loop:关键动作需要人类确认,例如付款、删库、发正式邮件、对外发布。
Prompt Injection:外部内容伪装成指令,诱导 Agent 越权执行。Agent 一旦能读网页、读邮件、跑命令,这类风险会明显放大。
Least Privilege:最小权限原则。只给 Agent 完成当前任务所需的最低权限,不把所有钥匙一次性塞给它。
3. 前沿项目与框架怎么放进同一张地图#
先纠正几个容易混的名字:
- Agent 不是模型名。它是一套围绕模型的执行系统。
- Hermes Agent 是 Nous Research 的开源 Agent 项目;“Hermes harness”更像口语化说法,不是一个独立官方产品名。
- Hermes-Function-Calling 是函数调用示例仓库,展示 Hermes Pro 模型如何按 schema 调用函数,不等于完整 Agent 框架。
- OpenHands 是 OpenDevin 的新名字。OpenHands 论文明确写着 OpenHands, f.k.a. OpenDevin。
- OpenClaw 和 OpenHands 不是一个项目。OpenClaw 更偏个人 AI 助理,OpenHands 更偏软件工程 Agent。
Hermes Agent#
Hermes Agent 的定位是开源、自托管、长期运行的 Agent。官方文档强调它支持终端、消息平台、IDE,多模型提供商,持久记忆、技能沉淀、插件、MCP、Webhook 和定时任务。
它的核心关键词是:
- 长期运行
- 跨会话记忆
- 从经验中沉淀 Skills
- 多入口触达
- 自托管和可扩展
适合的场景是私人助理、研究助手、定时报告、系统管理、内容生产、长期项目记忆。代价是部署、安全、密钥、权限和审计都需要自己设计。
OpenClaw#
OpenClaw 更像本地优先的个人 AI 助理。官方站点强调它运行在你的机器上,可以接入聊天应用,具备浏览器控制、文件读写、命令执行、Skills 和插件等能力。
它的优势是“真的能动手”:邮件、日历、浏览器、文件、脚本、自动化工作流都可以接进来。风险也来自这里:如果默认工具权限过大,Agent 的误操作和提示词注入风险会被放大。
所以 OpenClaw 这类项目最应该关注的不是“会不会聊天”,而是:
- 工具权限能否按任务收窄
- 是否有沙箱或隔离模式
- 远程入口是否需要强认证
- 第三方 Skill 是否经过审计
- 高风险动作是否有人类确认
OpenHands / OpenDevin#
OpenHands 是开源软件开发 Agent 平台。它的论文和 SDK 文档都把重点放在软件工程:写代码、改文件、跑命令、浏览网页、处理仓库任务,以及在沙箱环境里评测和执行。
它和通用个人助理的差异很明显:
- 任务对象主要是代码仓库
- 反馈信号通常来自测试、lint、类型检查、CI
- 工具集中在 Shell、文件编辑、浏览器、GitHub 工作流
- 更适合修 bug、重构、补测试、处理 PR 和仓库维护
OpenHands 的效果高度依赖仓库质量、测试覆盖率、Issue 描述和权限配置。一个没有测试、没有清晰验收标准的仓库,会让 Agent 很难判断自己是否真的完成了任务。
Manus#
Manus 是商业化的通用 Agent 产品案例。官方文档把它描述为能完成任务并交付结果的 autonomous general AI agent,并强调它在完整沙箱环境中运行,拥有互联网访问、持久文件系统、安装软件和创建自定义工具的能力。
它更像产品,而不是开发框架。用户关心的是“能不能把报告、网页、表格、分析、自动化任务交付出来”;开发者能控制的底层模型、工具编排、记忆机制和沙箱细节相对有限。
Hermes-Function-Calling#
这个仓库更适合当作“模型工具调用能力”的学习材料。它展示的是如何给模型提供函数 schema、让模型生成函数调用、再由外部代码执行。它解决的是 Agent 中“工具调用”这一块,不解决长期记忆、任务编排、权限、安全、观测和交付闭环。
| 项目 | 更准确定位 | 设计重点 | 典型场景 | 主要边界 |
|---|---|---|---|---|
| Hermes Agent | 开源、自托管、长期运行 Agent | 记忆沉淀、技能增长、多入口 | 私人助理、定时任务、长期项目 | 部署和安全要自己管 |
| OpenClaw | 本地优先个人 AI 助理 | 聊天入口、本机工具、个人自动化 | 邮件、日历、浏览器、文件自动化 | 权限很强,需要严格安全配置 |
| OpenHands / OpenDevin | 软件开发 Agent 平台 | 代码、Shell、浏览器、仓库工作流 | 修 bug、测试、重构、PR | 偏软件工程,不是生活助理 |
| Manus | 商业通用 Agent 产品 | 云端沙箱、端到端交付 | 调研、报告、网页、数据分析 | 黑盒程度较高,可控性有限 |
| Hermes-Function-Calling | 函数调用示例 | schema 工具调用 | 学习 function calling | 不是完整 Agent 系统 |
4. 架构与关系可视化#
下面这张图把两件事放在一起:上半部分是标准 Agent 内部闭环,下半部分是几个项目在生态中的位置。
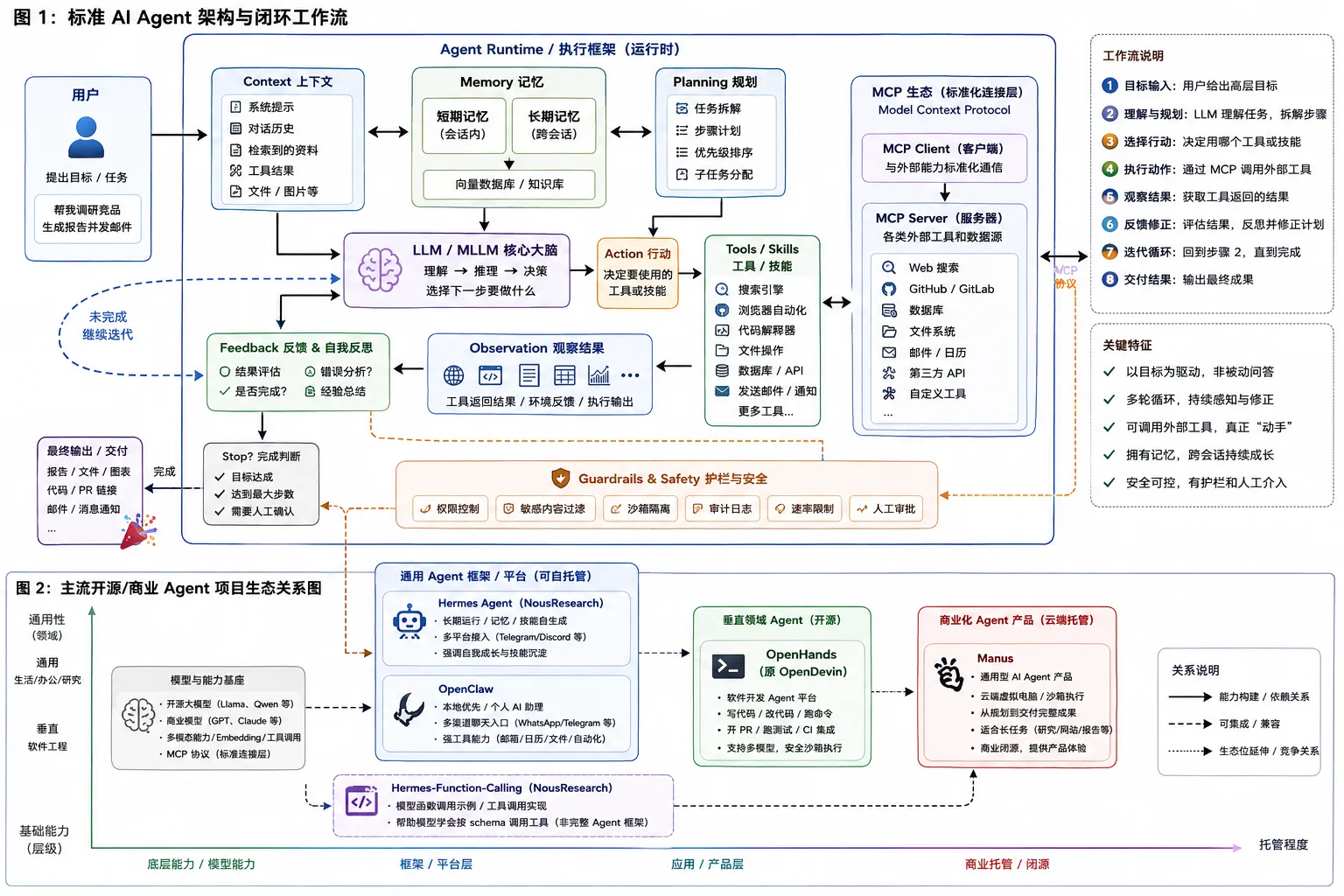
看图时重点抓住三条线:
- 主闭环:用户目标进入 Runtime 后,Context、Memory、LLM、Planning、Action、Tools、Observation、Feedback 循环协作。
- 工具接入层:Tools / Skills 可以直接接系统工具,也可以通过 MCP Client 连接多个 MCP Server。
- 安全边界:Guardrails 不应该是最后补上的模块,而应该横跨权限、工具调用、沙箱、审计和人工确认。
一个能上线的 Agent 系统,至少要回答这些工程问题:
- 它能看到哪些上下文?
- 哪些信息会写入长期记忆?
- 它如何拆解任务,如何更新计划?
- 它能调用哪些工具,每个工具有什么权限?
- 工具失败后怎么重试,什么时候停止?
- 哪些动作必须人工确认?
- 每一步有没有 trace,出错后能不能复盘?
5. 怎么判断一个东西是不是 Agent#
可以用一个很实用的判断标准:
如果系统只能生成回答,它是模型应用;如果系统能围绕目标持续规划、行动、观察、修正并交付结果,它才是 Agent。
更具体一点,至少看五个能力:
- 目标驱动:输入是高层目标,而不只是单轮问答。
- 状态管理:能维护任务状态、短期记忆和必要的长期记忆。
- 工具行动:能调用外部工具影响环境,而不是只生成文本。
- 反馈循环:能根据 observation 修正计划,而不是失败后直接结束。
- 安全治理:有权限、沙箱、审计、停止条件和人工确认。
也可以反过来判断伪 Agent:
- 只有一串 prompt chain,没有 observation。
- 能调用工具,但没有任务状态和停止条件。
- 有长期记忆,但没有权限隔离和审计。
- 会写代码,但不跑测试、不读错误、不验证结果。
- 能自动发邮件、改文件、调 API,却没有人工确认和回滚策略。
6. 总结#
Agent 的关键不是“模型更聪明”,而是“模型被放进了一个可执行、可观察、可反馈、可治理的系统里”。
MLLM 给 Agent 提供更强的感知和生成能力;Context 和 Memory 决定它能不能带着正确资料工作;Planning 决定它能不能把目标拆开;Tools 和 MCP 决定它能不能接触真实世界;Observation 和 Feedback 决定它能不能修正自己;Guardrails 决定它能不能安全地做事。
所以,当我们讨论 AI Agent 时,真正应该问的不是“它用了哪个模型”,而是:
它如何形成闭环?
它能调用什么工具?
它怎么知道自己做对了?
它什么时候会停?
它在什么动作前必须请人确认?这些问题回答清楚了,Agent 才从演示走向工程系统。
参考资料#
- ReAct: Synergizing Reasoning and Acting in Language Models ↗
- A Survey on the Feedback Mechanism of LLM-based AI Agents ↗
- Model Context Protocol Specification ↗
- Model Context Protocol Architecture Overview ↗
- Hermes Agent Documentation ↗
- NousResearch/hermes-agent ↗
- NousResearch/Hermes-Function-Calling ↗
- OpenHands Software Agent SDK ↗
- OpenHands: An Open Platform for AI Software Developers as Generalist Agents ↗
- OpenClaw 官方站点 ↗
- Manus Documentation ↗